Merge Sort in C++
I code a C++ function to implement Merge Sort Alg, which, I know, is not the best way to do it but able to represent the whole idea of it. In fact, I met some troubles in the beginning, and I am confused to it. So I checked the memory and recorded the values and addresses of critical variables. So I draw the following figure to help us understand the Merge Sort Alg in detail and how C++ works when implementing it.
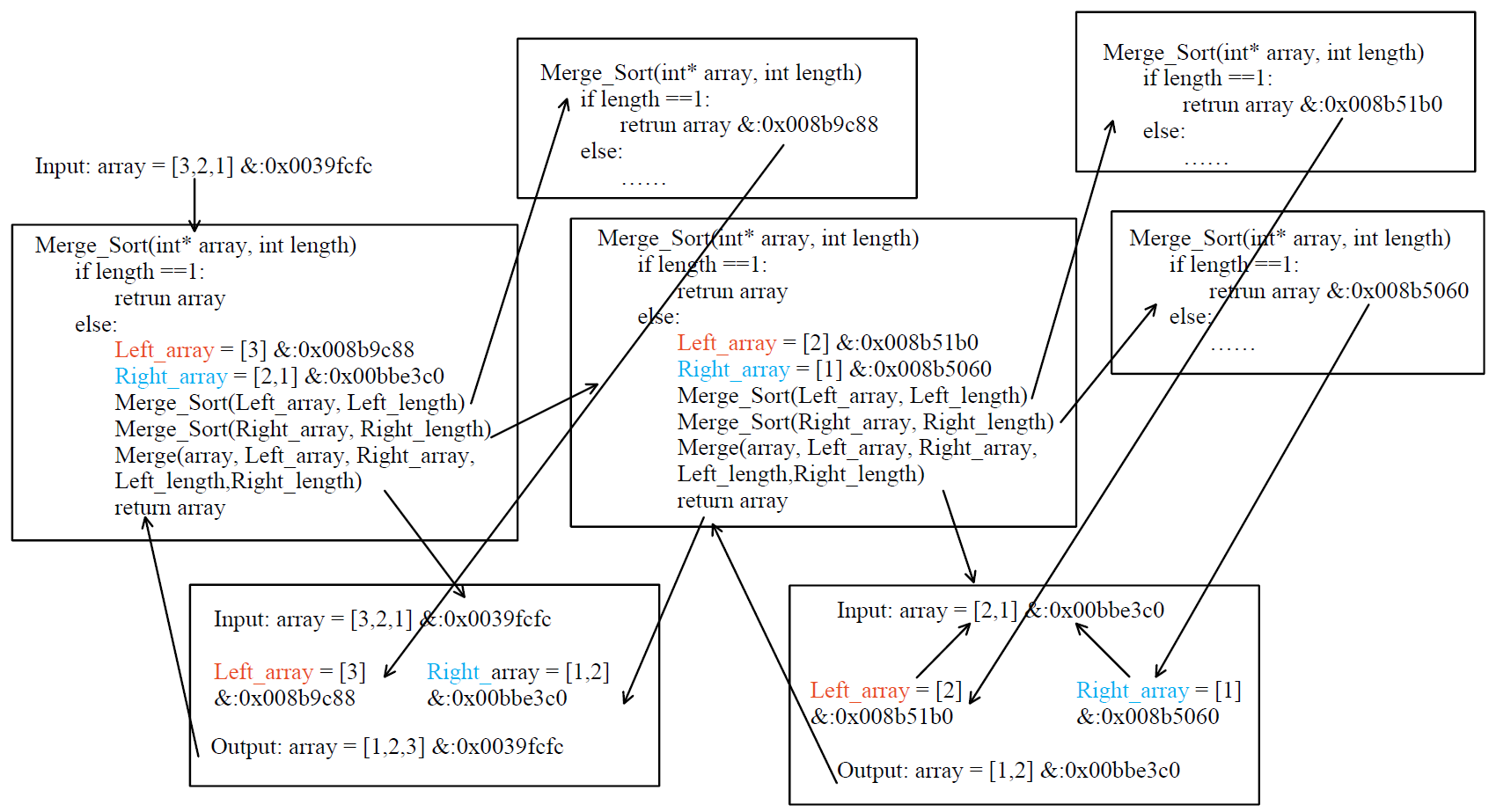
I thought the most important point is that we transfer the address of array to the ‘Merge’ function. Reviewing the whole process, when we creat Left_array and Right_array, computer wil assign new memory for them each time . And when they are merged through ‘Merge’ function (called ‘Merge_operation’ in Merge_Sort.cpp), actually, we input the address of original array (relative to current Left and Right array) to the function. That means, we permutate the number in original address (of original array). And ‘Merge_operation’ funtion will return the address of original array (and now it has sorted). This process guarantee the all arrays (or sub-arrays) in each level is sorted in original address (same as they were created).
Binary Search algorithm
The pseudocode for iterative binary search is shown in the following.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Iterative_Binary_search (A,v,n)
// A[1...n] is the sorted array
// v is the query number
// n is the length of the array
l = 1
r = n
while l <= r
m = [(l+r)/2]
if A[m] = v:
return m
else if A[m] < v:
l = m + 1
else:
r = m -1
return NIL
The recursive version is shown below in psudocode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Recursive_Binary_search (A,v,l,r)
// A[1...n] is the sorted array
// v is the query number
// l,r are left and right bounds,
// equal 1 and n in initialization
if l > r:
return NIL
else:
m = [(l+r)/2]
if A[m] == v:
return m
if A[m] < v:
Recursive_Binary_search (A,v,m+1,r)
else:
Recursive_Binary_search (A,v,l,m-1)
Note: here [x] means ${\lceil x \rceil}$.
Attention: when ${A[m] \neq v}$, the operation ${ l=m+1 }$ or ${r = m-1 }$ is necessary, otherwise, in some case, the program will never jump out of the loop.
For each version of binary search, we halve the range of searching each time, so the recurrence is
we can draw a recurrence tree (shown in below) to get the solution

Therefore, ${T(n)=\lg n \times \Theta(1) + \Theta(1)=\Theta(\lg n)}$
Binary Search in Insertion Sort
In each iteration, we can use Binary search to replace linear search in Insertion Sort Alg. Can we get a ${\Theta(n\lg n)}$ Alg? Actually, we cann’t! Because, in each loop, we not only need to search the proper postion for ${ A[j] }$ in ${ A[1…j-1] }$, but also execute the moving operation. And the worst case is moving all the ${ j-1 }$ elements, which takes ${ \Theta(j) }$ time. So in each iteration we take ${ \Theta(\lg j) }$ for search and ${ \Theta(j) }$ for moving. So the total time is also ${ \Theta(j) }$. Therefore, even we use binary search, the Insertion Sort is also a ${ \Theta(n^2) }$ Alg .
Search 2 nums whose sum is x
Given a set ${S }$ of ${ n }$ integers and another integer ${ x }$, determines whether or not there exist two elements in ${S }$ whose sum is exactly ${ x }$.
The whole idea is we iterate each element ${ i }$ in the set ${ S }$, and then check whether the ${ x-i }$ is in the set ${ S }$. And the second step we can use binary search. The pseudocode for above problem is shown in the following.
1
2
3
4
5
6
Search two element (S,x,n)
for i <- 1 to n:
pos = Iterative_Binary_search (S,x-i,n)
if pos != NIL:
return S[i] and S[pos]
return NIL
The running time of above ALg is easy to get. For each loop we take ${ \Theta(\lg n) }$ time, so the total time is ${ \Theta(n\lg n) }$.
Insertion sort on small arrays in merge sort
Although merge sort runs in ${ \Theta (n\lg n) }$ worst-case time and insertion sort runs in ${ \Theta(n^2)}$ worst-case time, the constant factors in insertion sort can make it faster in practice for small problem sizes on many machines. Thus, it makes sense to coarsen the leaves of the recursion by using insertion sort within merge sort when subproblems become sufficiently small. Consider a modification to merge sort in which ${ n/k }$ sublists of length ${ k }$ are sorted using insertion sort and then merged using the standard merging mechanism, where ${ k }$ is a value to be determined.
a. Show that insertion sort can sort the ${ n/k }$ sublists, each of length ${ k }$, in ${ \Theta (nk) }$ worst-case time.
Ans: For each sublist, we need ${ \Theta (k^2) }$ time to sort them through Insertion Sort Alg. So, all ${ n/k }$ sublists need ${ \Theta (k^2 \cdot n/k) = \Theta (nk)}$.
BUT! We need to notice that, if we consider ${ k }$ sublists of length ${ n/k }$, actually, the time we need is ${ \Theta \left( \left( \frac{n}{k} \right)^2 \cdot k \right) = \Theta \left( \frac{n^2}{k} \right) }$. Why? Becasue we separate list as a finite number ${ k }$ is quite different than a infinite number ${ n/k }$. For the second way, the lenght of sublist is ${ n/k }$ which relates to a infinite number ${ n }$, but the amount of sublist is a constant number, so the time we need is also ${ \Theta (n^2) }$.
b. Show how to merge the sublists in ${ \Theta (n \lg (n/k) ) }$ worst-case time.
Ans: we can merge 2 sublists of length ${ k }$ to a sublist of length ${ 2k }$ each time. Then we get ${ n/2k }$ sublists and continue merge these sublists. So, we need ${ \lg (n/k) }$ steps to do it. And for ${ i^{th} }$ merging, the time is ${ \Theta (2^i k) }$ for each two sublists, and we need do that for all the ${ \Theta \left( \frac{n}{2^i k} \right)}$ pairs of sublists. So we take ${ \Theta \left( \frac{n}{2^i k} \cdot 2^i k \right) = \Theta (n)}$ time in ${ i^{th} }$ merging. Therefore the total time of merging is ${ \Theta (n \lg (n/k)) }$
c. Given that the modified algorithm runs in ${ \Theta (nk+n \lg(n/k)) }$ worst-case time, what is the largest value of ${ k }$ as a function of ${ n }$ for which the modified algorithm has the same running time as standard merge sort, in terms of ${ \Theta }$-notation?
Ans: Consider following equation
So the large value of ${ k }$ is ${ c\lg n }$, ${ c }$ is a constant. So the large value of ${ k = \Theta (\lg n)}$.
d. How should we choose ${ k }$ in practice?
Ans: Choose ${ k }$ be the length of sublist on which insertion sort is faster than merge sort.
Correctness of Horner’s rule
The following code fragment implements Horner’s rule for evaluating a polynomial
given the coefficients ${ a_0, a_1,\cdots, a_n }$ and a value of ${ x }$:
1
2
3
y = 0
for i = n downto 0
y = a[i] + x*y
a. In terms of ${ \Theta }$-notation, the running time of this code fragment for Horner’s rule is ${ Theta (n) }$.
b. Write pseudocode to implement the naive polynomial-evaluation algorithm that computes each term of the polynomial from scratch. What is the running time of this algorithm? How does it compare to Horner’s rule
1
2
3
4
5
6
y = 0
for i = 0 to n
prod = 1
for j = 1 to i
prod = x*prod
y = y + a[i]*prod
The running time of above Alg is ${ \Theta(n^2) }$, which is shower than Horner’s rule.