本节课我们介绍MLP和CNN的代码实现,我们从Pytorch的安装开始说起。
Pytorch的安装
Pytorch的安装比较简单,我们可以看到下图的选择栏目,根据你的需要,下面会自动生成合适的命令,把命令copy到command line里,就可以完成安装。
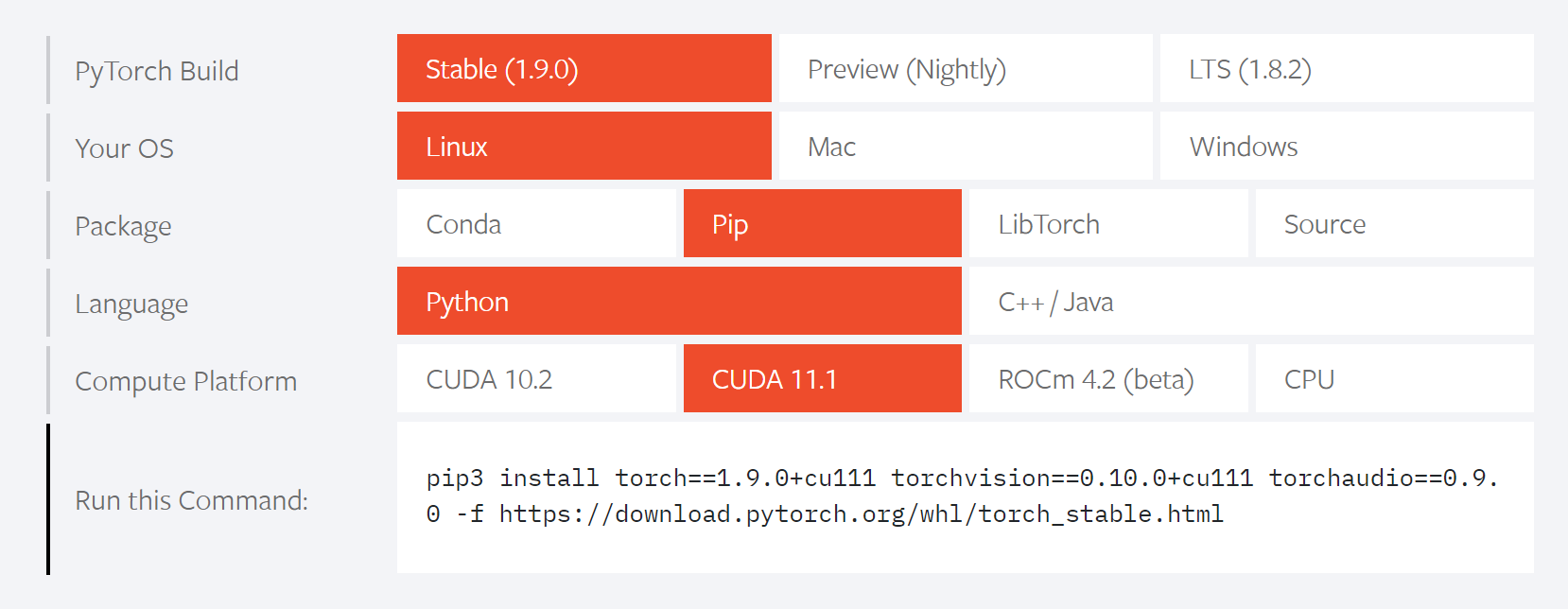
可以在python shell里检查一下
1
2
3
>>> import torch
>>> torch.__version__
'1.9.0+cpu'
深度学习流程
我先简单的介绍一下深度学习的整个代码框架,我做了下面的一个流程图。大致分为这些模块和步骤。
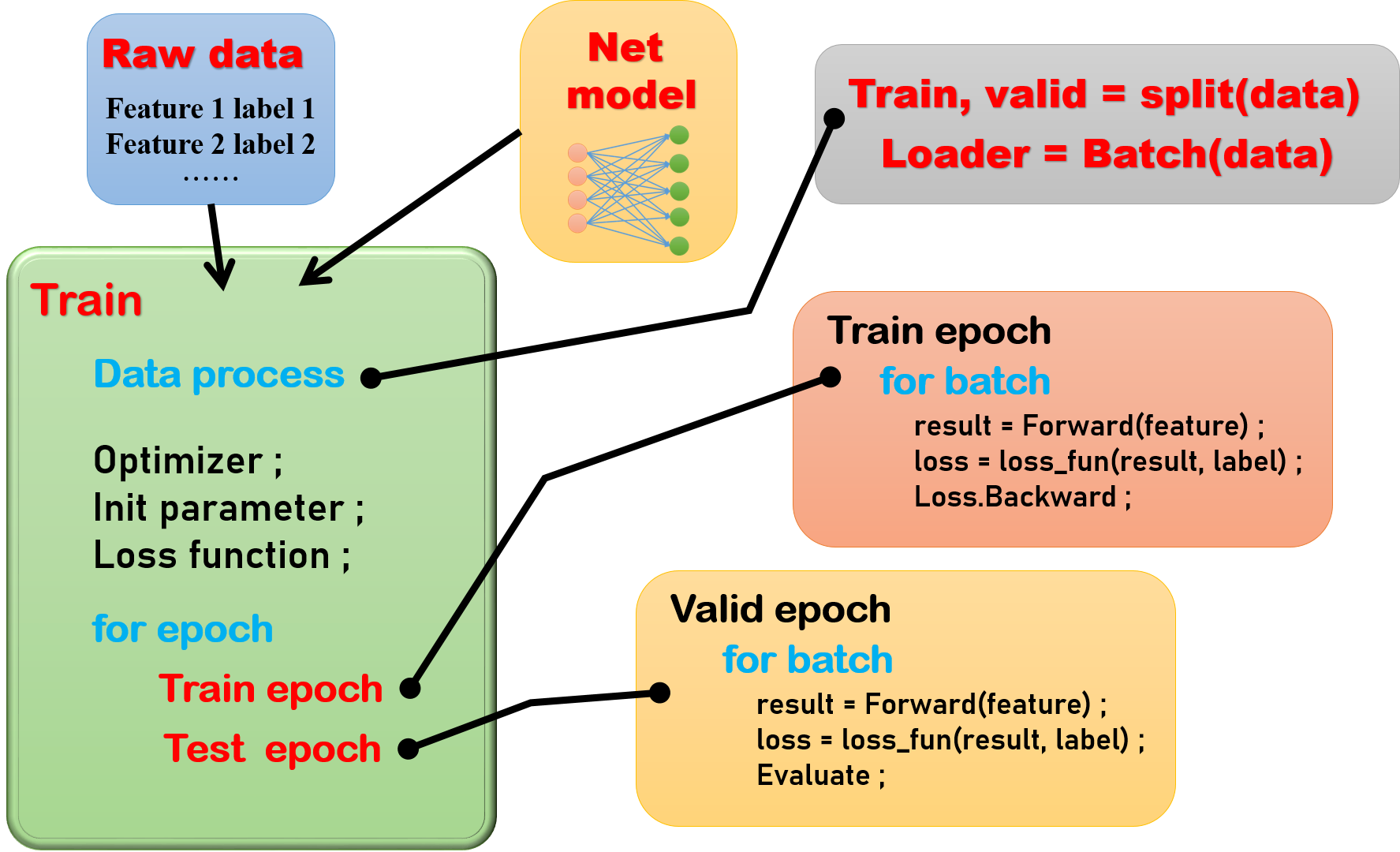
原始的输入数据部分这个比较容易理解,我们一般输入的结构都是特征和标签两部分,当然这个也不一定,依据你们自己设计的模型和框架进行调整。
网络模型部分呢,其实本质上是一个类,从torch.nn.Module继承而来。然后我们从torch里面选择合适的函数,来搭建我们自己的网络。所以我们每次使用的时候,就是初始化这个类的一个实例。
然后我们进入到这个代码的主要部分,训练部分,首先我们需要对数据进行处理,例如随机切分训练集、验证集,将数据分成batch。然后,我们进行一些准备工作,例如选择一个合适的优化器,初始化模型参数,定义损失函数等等。
下面就来到了关键部分,我们需要对网络训练若干次,每一个epoch都要经历两个过程,训练过程、验证过程。对于训练过程,就是正向传播,计算损失函数,然后反向传播。验证过程,只需要正向传播,计算损失,不需要反向传播,但是可以根据自己的需要加入一些评价的过程,比如计算准确率,召回率等等。
数据处理
Tensor
在数学上,一维的数组是向量,二维的数组是矩阵,更高维度的数组就是张量。在深度学习里面我们的数据往往维度很高,举个例子,比如一组图片的数据,在网络学习的时候往往有四个维度${ (B,C,L,W) }$,${ B }$是batch的维度,${ C }$是channel的维度,${ (L,W) }$是图片的长宽。
在pytorch里面,各种计算和优化都是基于Tensor这个数据类型的。但是Tensor的各种操作特别繁多,也不复杂,更重要的是与Python常用的库Numpy的数组操作基本类似,所以这里只介绍简单的一些操作。遇到特殊的情况,可以去torch的官网,寻找你需要的计算函数。还有一个需要注意的地方,在Pytorch的0.4版本之前,Tensor不能直接计算梯度,需要先用Variable类处理一下,才能扔进网络里,但是后面Tensor和Variable合并了,所以这个操作做不做都一样,但是有很多代码还保留了这样的写法,或者仍然习惯这么去写。
1.from List
从Python的list生成,注意如果需要求梯度,数据类型一定需要浮点数才可以计算。
1
2
3
4
>>> torch.tensor([[0.1, 1.2], [2.2, 3.1], [4.9, 5.2]])
tensor([[ 0.1000, 1.2000],
[ 2.2000, 3.1000],
[ 4.9000, 5.2000]])
反过来和Numpy一样,我们也可以将tensor转化回list
1
2
a = torch.tensor([[0.1, 1.2], [2.2, 3.1], [4.9, 5.2]])
a = a.tolist()
2.from Numpy
从Numpy的数组生成tensor
1
2
3
>>> a = numpy.array([1.,2.,2.])
>>> torch.from_numpy(a)
tensor([1., 2., 2.], dtype=torch.float64)
同样,我们也可以将tensor转成numpy
1
2
3
4
5
>>> a = torch.tensor([[0.1, 1.2], [2.2, 3.1], [4.9, 5.2]])
>>> a.numpy()
array([[0.1, 1.2],
[2.2, 3.1],
[4.9, 5.2]], dtype=float32)
3.reshaping
因为很多Pytorch的函数输入的尺寸要求不同,所以我们往往需要给tensor数据整形,比如你的数据是${ (B,L,W) }$,如果想要输入卷积层,就需要添加一个channel的维度,变成${ (B,1,L,W) }$,或者有时候我们想把矩阵转化成一个向量,扔进全连接层都需要整形。我们下面介绍几个整形的函数
view()/reshape()
这两个函数差别不大,把你想整形成的维度输入放在括号里面就可以了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
>>> X = torch.tensor([[1,2,3,4],[5,6,7,8],[1,2,5,6]])
>>> X.view(1,12)
tensor([[1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 5, 6]])
>>> X = torch.tensor([[1,2,3,4],[5,6,7,8],[1,2,5,6]])
>>> X.view(3,1,4)
tensor([[[1, 2, 3, 4]],
[[5, 6, 7, 8]],
[[1, 2, 5, 6]]])
>>> X.reshape(1,3,4)
tensor([[[1, 2, 3, 4],
[5, 6, 7, 8],
[1, 2, 5, 6]]])
>>> X.reshape(2,6)
tensor([[1, 2, 3, 4, 5, 6],
[7, 8, 1, 2, 5, 6]])
squeeze()
比如我们在处理数据的时候,很有可能会出现有些维度是${ 1 }$,比如图片数据的Channel维度,我们想把这些空维度给压缩掉,就可以简单的使用squeeze()
1
2
3
4
5
6
7
8
9
10
11
12
>>> a = torch.tensor([[[1, 2, 3, 4]],
[[5, 6, 7, 8]],
[[1, 2, 5, 6]]])
>>> a.shape
torch.Size([3, 1, 4])
>>> a.squeeze()
tensor([[1, 2, 3, 4],
[5, 6, 7, 8],
[1, 2, 5, 6]])
>>> a = a.squeeze()
>>> a.shape
torch.Size([3, 4])
flatten()
flatten()比较容易理解,就是将张量直接拉平。
1
2
3
4
5
>>> a = torch.tensor([[[1, 2, 3, 4],
[5, 6, 7, 8],
[1, 2, 5, 6]]])
>>> a.flatten()
tensor([1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 5, 6])
数据切分、加载
构建自己的数据集,我们训练的时候,需要将feature和label组合在一起,一起划分、一起分割batch,我们可以用到下面这个函数torch.utils.data.TensorDataset,当然有时候我们的特征不只有一个部分,比如我们可以有一个矩阵的特征还有一个一维的特征,它们也许被分别处理之后,再拼接到一起,我们仍然可以将它们打包到一个数据集。
1
2
3
import torch.utils.data as data
train_feature_label = torch.utils.data.TensorDataset(train_feature_1, train_feature_2, train_label)
然后,我们可以进行数据加载,使用torch.utils.data.DataLoader将数据集加载,同时将数据集分成batch,大家可以用for循环打印观察一下train_loader,每个元素就是一个batch的数据,如果不太能理解,我们一会儿有实例,可以展示一下。(shuffle表示是否打乱顺序)
1
train_loader = torch.utils.data.DataLoader(dataset=train_feature_label, batch_size=32, shuffle=True)
当然了,我们这里面还有一个参数可以选择sampler=?? ,也就是我们可以按照我们的需要选择样本加载。比如,我们可以根据行号随机切分训练集、验证集。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from torch.utils.data.sampler import SubsetRandomSampler
samples_num = len(feature_label)
split_num = int(0.9 * samples_num)
data_index = np.arange(samples_num)
np.random.shuffle(data_index)
train_index = data_index[:split_num]
valid_index = data_index[split_num:]
train_sampler = SubsetRandomSampler(train_index) # 初始化一个类,输入一个索引,后面DataLoader按照这个索引采样
valid_sampler = SubsetRandomSampler(valid_index)
train_loader = torch.utils.data.DataLoader(dataset=feature_label, batch_size=BATCH, sampler=train_sampler)
valid_loader = torch.utils.data.DataLoader(dataset=feature_label, batch_size=BATCH, sampler=valid_sampler)
网络搭建
然后我们现在进入,比较关键的地方,搭建我们自己的网络。所谓的网络就是继承自nn.Module的一个类,我觉得网络主要分为两个部分,一个是初始化部分,一个是forward(),即前向传播部分。所谓的初始化部分,我觉得就是先配齐一个工具箱,你所需要的全连接层,卷积层,池化层,激活函数这些部件都实现准备好。所谓的forward()前向传播部分,就是将这些零件一个一个的组装起来。
1
2
3
4
5
6
7
8
9
10
11
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
############
#配置各种零件#
############
def forward(self, x):
############
#零件依次摆放#
############
return out
MLP网络
下面我们随便搭建一个MLP网络,尝试一下。我们先在初始化部分,构建好各个层,比如我们准备设计三个层,输入维度是128,然后进入64维度的隐藏层,然后输出层是尺寸是1,使用的函数就是nn.Linear()。最后来个Sigmoid函数,把取值限制在[0,1]。然后激活函数选ReLU(),dropout设置成0.5。
前向传播forward()部分就是把定义好的零部件挨个串起来就完成了。看起来是不是也挺简单的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.DROPOUT = 0.5
self.fc1 = nn.Linear(in_features=128, out_features=64, bias=True)
self.fc2 = nn.Linear(in_features=64, out_features=32)
self.fc3 = nn.Linear(in_features=32, out_features=1)
self.dropout = nn.Dropout(self.DROPOUT)
self.ac = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.fc1(x)
out = self.dropout(out)
out = self.ac(out)
out = self.fc2(out)
out = self.dropout(out)
out = self.ac(out)
out = self.fc3(out)
out = self.sigmoid(out)
return out
当然了,这种写法非常的麻烦,才三层的MLP就写了这么多行。我们可以用nn.Sequential()在初始化部分就把部分零件串联起来。这样我们的forward()部分就简化很多。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.DROPOUT = 0.5
self.fc1 = nn.Sequential(nn.Linear(in_features=128, out_features=64),nn.Dropout(self.DROPOUT),nn.ReLU())
self.fc2 = nn.Sequential()
self.fc2.add_module('fc',nn.Linear(in_features=64, out_features=32))
self.fc2.add_module('Drop', nn.Dropout(self.DROPOUT))
self.fc2.add_module('ReLU', nn.ReLU)
self.fc3 = nn.Sequential(nn.Linear(in_features=32, out_features=1), nn.Dropout(self.DROPOUT))
self.fc3.add_module('Sigmoid',nn.Sigmoid())
def forward(self, x):
out = self.fc1(x)
out = self.fc2(out)
out = self.fc3(out)
return out
还有些同学觉得,这个也很麻烦,我如果有多个隐藏层,要写很多,改个隐藏层个数的超参数也很麻烦,那么可以用下面这个函数nn.ModuleList(),可以像List一样将网络层接在一起。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.DROPOUT = 0.5
self.LAYERS = 8
self.fc1 = nn.Sequential(nn.Linear(in_features=128, out_features=64),nn.Dropout(self.DROPOUT),nn.ReLU())
self.fc2 = nn.ModuleList()
for _ in range(self.LAYERS):
fc = nn.Sequential(nn.Dropout(self.DROPOUT), nn.Linear(64, 64), nn.ReLU())
self.hidden.append(fc)
self.fc3 = nn.Sequential(nn.Linear(in_features=32, out_features=1), nn.Dropout(self.DROPOUT))
self.fc3.add_module('Sigmoid',nn.Sigmoid())
def forward(self, x):
out = self.fc1(x)
for i in range(LAYERS):
out = self.fc2[i](out)
out = self.fc3(out)
return out
CNN网络
那么如果前面的MLP已经了解的话,搭建一个卷积的网路,也非常简单,这里随便给个例子,nn.Conv2d()是二维的卷积,我们前两个参数分别表示channel是输入输出个数,后面表示卷积核的size,padding表示补零列数(行数)的情况。nn.MaxPool2d()是最大池化(2,3)是池化核的形状。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.kernel_size = 3
self.conv = nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=2,
kernel_size=(self.kernel_size,self.kernel_size),
padding=self.kernel_size//2),
nn.MaxPool2d((2,3),padding=self.kernel_size//2),
nn.ReLU())
self.fc = nn.Sequential(nn.Linear(64, 1), nn.Sigmoid())
def forward(self, x):
out = self.conv(x)
out = out.flatten()
out = self.fc(out)
return out
网络训练
下面我们来到了另一个重要的模块,就是网络训练我们分成几个部分来介绍。首先,可以用前面数据处理的几个函数,先完成数据的准备工作。然后,大概写个框架,我们需要那些函数核变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import torch
import torch.nn as nn
import torch.utils.data
from torch.utils.data.sampler import SubsetRandomSampler
import torch.optim as optim
import torch.nn.functional as F
model = Net()
def train_epoch():
return
def valid_epoch():
return
def train(model,feature_label):
samples_num = len(feature_label)
split_num = int(0.9 * samples_num)
data_index = np.arange(samples_num)
np.random.shuffle(data_index)
train_index = data_index[:split_num]
valid_index = data_index[split_num:]
train_sampler = SubsetRandomSampler(train_index)
valid_sampler = SubsetRandomSampler(valid_index)
train_loader = torch.utils.data.DataLoader(dataset=feature_label,
batch_size=BATCH, sampler=train_sampler)
valid_loader = torch.utils.data.DataLoader(dataset=feature_label,
batch_size=BATCH, sampler=valid_sampler)
初始准备
我们初始化的准备,就是三项:1.模型参数初始化;2.优化器的设定;3.损失函数设置; 其实很简单的两行代码就可以解决,关于参数初始化这里写的就是最简单是随机初始化,其实还有很多初始化的方式,比如均匀分布、正态分布等等,这里不再赘述,可以去官网寻找,采用合适的方式即可。优化器此处用的是Adam,损失函数是二项交叉熵,也都可以替换,采用合适的即可。
1
2
3
4
5
import torch.optim as optim
import torch.nn.functional as F
optimizer = optim.Adam(model.parameters(), lr=0.001)
loss_fun = F.binary_cross_entropy
然后我们开始进入每个epoch的训练,先写个大致的框架
1
2
3
4
5
EPOCH = 30
for epoch in range(EPOCH):
loss_t = train_epoch(model, train_loader, optimizer, loss_fun)
loss_v = valid_epoch(model, valid_loader, loss_fun)
train epoch
下面我们具体写一下训练一个epoch的代码,model.train()是含义是将模型调整成训练状态,另一个状态是model.eval(),在训练状态下,比如dropout这类随机的情况是随机发生的,但是eval模式先,这种随机状态就被固定。
首先将变量变成可求梯度的状态,然后我们将梯度归零,进行前向传播,进一步计算损失函数,最后计算梯度,优化器优化参数。
最后很简单,我们给验证集每个样本的损失计算一个平均值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def train_epoch(model,train_loader, optimizer, loss_fun):
model.train()
loss = 0
num = 0
for step, (feature, label) in enumerate(train_loader):
feature = torch.autograd.Variable(feature.float())
label = torch.autograd.Variable(label.float())
optimizer.zero_grad()
output = model(feature)
train_loss = loss_fun(output, label).to(DEVICE)
train_loss.backward()
optimizer.step()
loss = loss + train_loss.item()
num = num + len(label)
epoch_loss = loss / num
return epoch_loss
valid epoch
训练epoch已经说明了,验证epoch就很简单了。with torch.no_grad()的作用是下面的代码都不会进行梯度计算,所以可以节省一些GPU资源,加速代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def valid_epoch(model, valid_loader, loss_fun):
model.eval()
loss = 0
num = 0
with torch.no_grad():
for step, (feature, label) in enumerate(valid_loader):
feature = torch.autograd.Variable(feature.float())
label = torch.autograd.Variable(label.float())
pred = model(feature)
valid_loss = loss_fun(pred, label)
loss = loss + valid_loss.item()
num = num + len(label)
epoch_loss = loss / num
return epoch_loss
模型保存与加载
当我们需要最终确定进行保存的时候,我们可以用下面两种方式保存模型和加载模型。
1.保存整个模型
1
2
torch.save(model,"./model/Net.pkl")
model = torch.load("./model/Net.pkl")
2.只保存模型的参数
1
2
3
torch.save(model.state_dict(),"./model/Net.pkl") # 存成.dat文件也可以
model = Net() # 创建一个实例
model.load_state_dict(torch.load('./model/Net.pkl')) # 模型的参数被赋值
run on GPU
GPU上运行,需要使用cuda,为了防止没有cuda而不能运行程序,这里事先检测一下cuda的存在性.
1
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # cuda:0是为了防止有多个GPU,因为张量运算需要在同一个GPU才能运行.
然后,将操作放在GPU上有两种方法
1
2
XXX.cuda() # No.1
XXX.to(DEVICE) #前面定义的DEVICE
举例如下,注意进行GPU运算的所有张量都要事先传入GPU,必须在同一设备下,一定切记!
1
2
3
4
model = MyConvNet().to(DEVICE)
for epoch in range(30):
for step, (feature, label) in enumerate(train_loader):
feature, label = feature.to(device), label.to(device)
最后,需要注意的就是,计算的结果如果再进一步计算的话,需要注意,可能需要再切换回CPU,使用XXX.cpu()即可。