下面这个部分,我们将介绍变分图自编码网络,为了让大家更好的理解,我们从自编码网络开始一点点的介绍。这些自编码的网路,其实主体的流程都是比较接近的,大致分为两步,encoding和decoding,也就是编码和解码。我认为,编码的过程就是数据压缩的过程,也就是一个信息提取、精炼的过程。那么,我怎么去判断我提取的这个信息到底准确与否呢,我再去解码,看看能不能尽量的和原先的信息尽量的接近。
那么自编码网路能干嘛呢,我们可以用来做特征提取,信息去噪,数据降维,信息补全,等等吧。对于更高级的编码、解码的网络我们可以用来做图片生成、语言生成(这两个问题,我也不是十分了解,有一些应用,比如从低清晰度的图片生成高清的图片,语言生成大致是解决一些seq2seq的问题,也许比如你跟机器人对话、把中文流畅的翻译成英语等等,如果这部分我说的不对,还请大家批评指正),用图自编码我们可以做链路预测。
关于最简单AutoEncoder在这里就不做太多介绍了,你可以只用三层神经网络去实现,输入层、隐藏层、输出层。损失函数就是输入和输出的差异。
VAE
事先说明,对于VAE的理解,也许我可能理解的有偏差,而且原文的很多推导涉及很多概率的知识,我自己能力有限可能不能完全理解,我也只能在自己的能力范围内,通过资料和源代码,去解释VAE的大致原理。再者,本文的重点在于教大家使用,对于原理的准确推导不做深究,大家见谅。
变分自编码网络的假设真实的样本服从某一种复杂的分布模式,而我们呢,希望去通过变换,将原始的分布映射成标准的正态分布,也就是说,我们的输入是${ X\sim P(X) }$,我们希望将嵌入到一个新的空间,也就是编码成隐藏变量${ Z }$,让${ Z \sim N(0,I)}$。然后,我们能从标准正态分布${ N(0,I) }$中采样,然后用解码器去生成样本。但是这样有一个问题,因为我们不知道原始的样本服从何种复杂的分布,我们根本没法去比较生成的样本和实际样本的分布到底差距是多少。而且,还有一个问题,如果我们直接去衡量${ x_k }$与${ \hat{x}_k }$的差异,也没有道理,因为每个${ z_k }$都是从正态分布采样来的,所以${ z_k,z_j,z_i }$等等,没有什么差别。
那么我们可以换个思路,这里我们只讨论思路,具体的数学公式可能不太严谨。实际上,VAE完全没有去使用${ P(Z) }$是正态分布的假设,我们采用的假设是${ p(Z\mid x_k) }$服从独立的正态分布,也就是我们给每个${ x_k }$分配了一个专属的正态分布${ P(Z\mid x_k) }$,我们再从${ P(Z\mid x_k) }$采样一个${ z_k }$,我再用${ z_k }$去还原原始的样本${ \hat{x}_k }$,这时候我们认为,这样还原的${ \hat{x}_k }$就受到了${ x_k }$的限制,这样去比较你们二者的差异,就是合理的。
现在问题来了,怎么计算${ P(Z\mid x_k) }$,我们需要求两组参数,方差${ \sigma^2 }$和均值${ \mu }$,关键我们就一个样本,怎么求分布呢?那么,神经网络的思路就来了,搞两个神经网络,把${ x_k }$映射成两个向量,一个就认为是均值,一个就认为方差,后面我们去优化就行了。具体而言,我们映射成的是${ \mu,log \sigma^2 }$,因为${ \sigma^2 }$总是正的,所以我们换成拟合${ log \sigma^2 }$。
好了,现在我们可以放心把损失函数刻画成${ x_k,\hat{x}_k }$的差异,这时候我们站在网络的角度思考,你不是让我模仿${ x_k }$吗?那干脆,直接我把${ \sigma^2 }$干成0,你这样每次采样就是死的,就是均值,损失肯定小啊。这样一想呢,前面这一堆花里胡哨的啥用没有,现在的网络就是最简单的自编码网络,从${ X }$生成${ Z }$,${ Z }$再重构${ \hat{X} }$。
所以,我们得加点限制,让${ P(Z\mid X) }$都尽可能的接近标准正态分布${ N(0,I) }$,而且这样还有一个好处
按照这个要求,${ P(Z) }$也越来越接近正态分布,那么对于生成器(decoder)而言是个好事情,这样的话,我随便从${ N(0,I) }$里面采样,生成器都能造假出来样本,非常的方便。而且,我个人觉得,这个过程其实也是引入噪声的环节,毕竟完全没有噪声,编码解码没大意思,加点噪声编码、解码的能力都会提高。(个人意见)
那么,很自然,我们得衡量${ P(Z\mid X) }$与${ N(0,I) }$的差异,文章使用了KL散度,推导不再给出,直接给结果
最后还有一个问题,怎么采样呢?每个${ P(Z\mid x_k) }$都要采样,但是采样是随机的,没法求导啊,怎么反过来优化前面的参数呢?如果要是这个随机的采样是一个固定的数字就好了,这样他就是输入的一部分了,只不过每次都不一样。这里就用到了,文章的重参数技巧。我们每次其实从${ N(0,I) }$中采样${ \varepsilon }$,采样之后让${ z = \varepsilon \bullet \sigma +\mu }$计算一下,此时${ z \sim N(\mu,\sigma^2) }$,这样好了,${ \varepsilon }$每次是一个确定的量,不用进行优化,优化${ \mu,\sigma^2 }$就行了。
VGAE
有了前面VAE的铺垫,下面我们进入最终想介绍的模型VGAE,变分图自编码模型。有了VAE之后,VGAE就非常好理解了,我们的编码器是两个图卷积,分别生成${ \mu,\log \sigma^2 }$,只不过这里的限制不仅仅有${ x_k }$还有${ A }$,也就是图的结构限制。具体而言,原文是这样设计的,特征和邻接矩阵扔进第一层图卷积后,再分别接入两个图卷积,来计算方差、均值。然后用,重参数的方法进行采样。如此,我们得到了隐变量${ Z }$,进一步我们用${ sigmoid(Z^TZ) }$来重构邻接矩阵(${ z^T_iz_j }$表示${ i,j }$连边的概率)。损失函数也是两部分,第一部分是原始图与生成图之间的差异,第二部分是${ P(Z\mid X,A) }$与标准正态分布的KL散度差异。
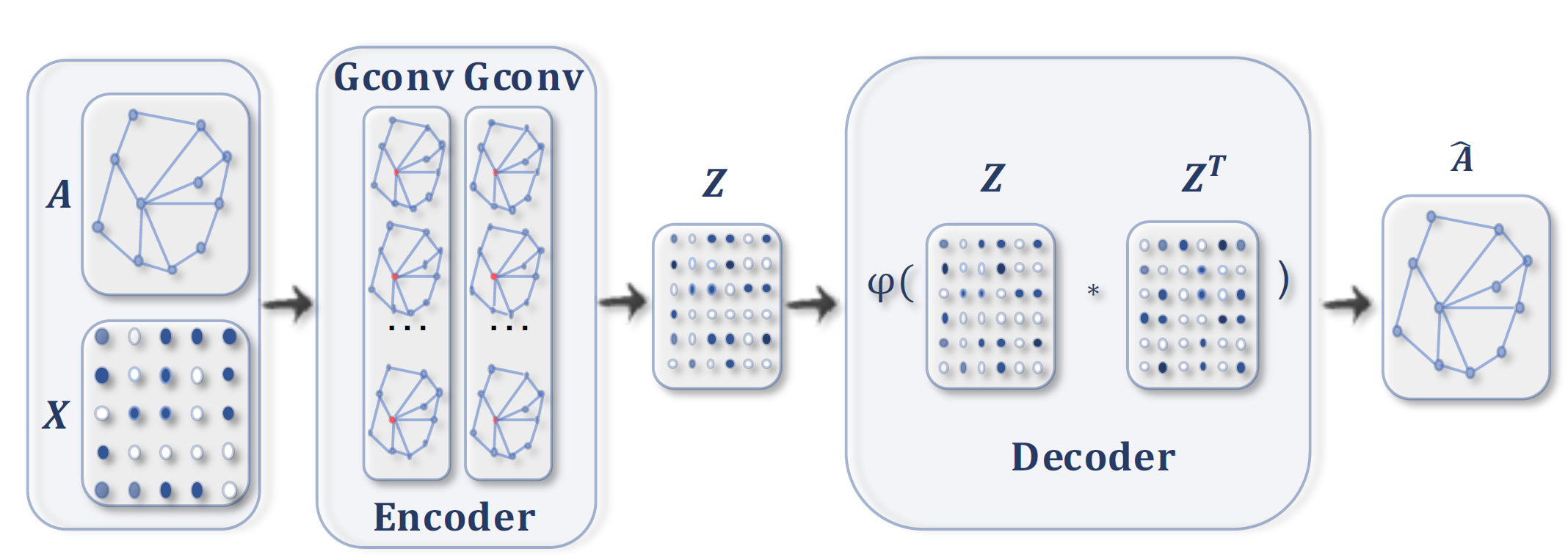
VGAE1.
GAE
在VGAE的论文最后,作者还给了一个简化的版本,也就是GAE图自编码,非常的简单,编码器是两层GCN,解码器还是${ sigmoid(Z^TZ) }$,损失函数只计算原始图与生成图的差异。