这个教程是总结前一段时间自己学习并且动手深度学习的过程. 主要包括pytorch的安装、网络模型的搭建、以及训练,并且涉及将代码放在GPU上运行.
Pytorch的安装
首先进入Pytorch官网, 然后,我们会看到下面的一个选择框,选择适合的命令进行安装.
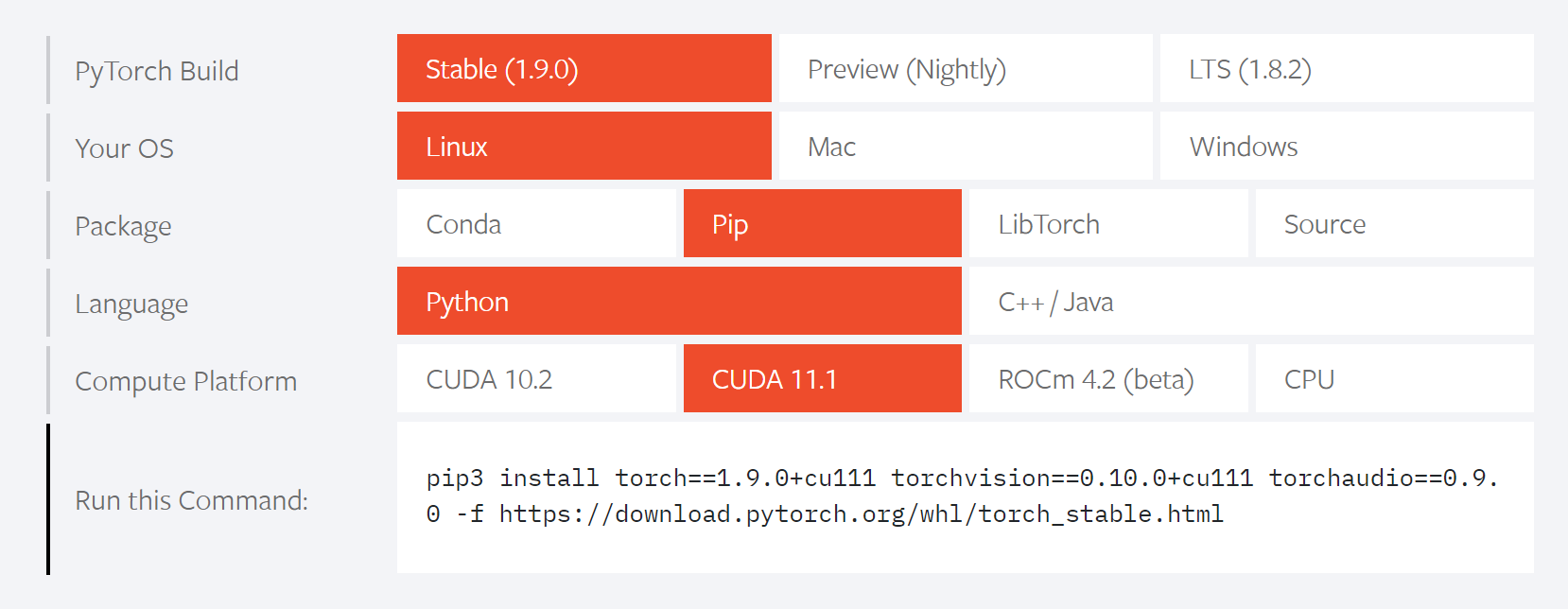
如果没有安装cuda可以选择CPU版本,但是运行速度确实很慢.
如果有cuda的情况下,可以安装相应的版本,我在服务器上安装的时候遇到了空间不足的错误. 可以用下面的方式解决.
1
2
3
4
5
$ cd~
$ mkdir tmp # 已经有可以省略
$ export TMPDIR=$HOME/tmp
$ pip3 install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio===0.9.0
-f https://download.pytorch.org/whl/torch_stable.html
pytorch的操作中离不开张量tensor的操作,由于过于繁琐,请大家参看pytorch的官方文档.
网络模型的搭建
搭建网络,其实就是创建一个你所定义网络的类,这个类继承自 nn.Module,所以事先import torch.nn
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import torch
import torch.nn as nn
class MyConvNet(nn.Module):
def __init__(self):
super(MyConvNet,self).__init__() #继承类的开头
self.conv1 = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3, 3) ,padding=0)
self.conv2 = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3, 3), padding=0) #定义自己的卷积层
self.fc1 = nn.Linear(21,1024) #全连接层
self.dropout = nn.Dropout(0.2) #设置dropout比率
self.fc2 = nn.Linear(1024,256) #注意全连接层之间的输入核上一层的输出保持一致
self.fc3 = nn.Sequential(nn.Linear(256,2),nn.Sigmoid())
def forward(self,x,DCGR_feature):
shape = x.shape
out = self.conv1(x)
out = F.relu(out) #激活函数
out = self.conv2(out)
out = F.max_pool2d(out, 2, 2) #池化层
out = F.relu(out)
out = torch.reshape(out,(shape[0],1,21)) #将张量形状改变
out = self.fc1(out)
out = F.relu(out)
out = self.dropout(out)
out = self.fc2(out)
out = F.relu(out)
out = self.fc3(out)
return out
model = MyConvNet() #申请一个网络的实例
着重看一下下面代码中的几个函数
1.nn.Conv2d()
1
2
nn.Conv2d(in_channels=1, out_channels=1, kernel_size=(3, 3) ,padding=0)
# 分别表示卷积层的进入通道数目,输出通道数目,以及卷积核的尺寸,padding是为了给图片补值来保证卷积扫描后图片尺寸不变
所谓的通道数目,在实际意义上,可以代表比如彩色图片RGB三个值,就是三个通道. 然后后面的通道数目,可以理解为用不同的卷积核来提取特征.
2.nn.Sequential()
1
nn.Sequential(nn.Linear(256,2),nn.Sigmoid())
这个函数是为了将一些连续的操作集成在一起.
模型训练
数据加载和batch
因为我们训练的时候,需要将数据对应起来,feature和标签,甚至有feature由好几个部分组成,我们需要统一的处理batch,所以我们可以用到torch.utils.data.TensorDataset()这个函数,这个操作可以理解为打包,只要他们的样本数目一致,就可以打包,后面就可以统一处理.
1
2
3
4
import torch.utils.data
from torch.utils.data.sampler import WeightedRandomSampler
train_feature_label = torch.utils.data.TensorDataset(train_feature_1, train_feature_2, train_label)
在深度学习中,我们通常将数据分成batch,每次训练的时候以batch为一个单位,迭代一个batch的数据更新一次参数,主要是因为数据量大而节省开销. 那么分成epoch的方法如下
1
2
3
4
sampler = WeightedRandomSampler(weights=list(0.85 if i == 1 else 0.1 for i in train_label),
num_samples=len(train_label), replacement=True)
train_loader = torch.utils.data.DataLoader(dataset=train_feature_label, batch_size=32
, sampler=sampler)
注意到,这里有一个sampler参数,也就是batch采样的参数,这里我使用的是一种随机权重采样WeightedRandomSampler(),可以用于数据不平衡,保证每个batch是均衡的,这个函数的参数部分,weights需要赋值一个list,这个list是所有样本的权重分配list. 做好上面准备之后,我们就可以进行训练了.
epoch训练和测试
首先选择合适的损失函数,以及优化方法,如随机梯度下降,或者Adam()
1
2
3
4
5
import torch.optim as optim
loss_fun = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# model.parameters()模型参数初始化
然后进行epoch训练,因为模型将样本的所有数据喂一遍不足以收敛,所以往往进行很多轮次训练
1
2
3
4
5
6
7
8
for epoch in range(30): # 30轮训练
for step, (D, G, L) in enumerate(train_loader):
# 因为我前面是三部分数据 feature_1,feature_2和标签
output = model(D.float(), G.float())
train_loss = loss_fun(output, L) # loss函数.
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
这就完成了一次模型的参数训练,类似的,每次每次模型参数迭代后,可以进行一次测试集的测试,也记录下loss值,这里不再详细介绍,会训练,自然会test处理.
在GPU上运行
GPU上运行,需要使用cuda,为了防止没有cuda而不能运行程序,这里事先检测一下cuda的存在性.
1
2
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# cuda:0是为了防止有多个GPU,因为张量运算需要在同一个GPU才能运行.
然后,将操作放在GPU上有两种方法
1
2
3
4
# No.1
XXX.cuda()
# No.2
XXX.to(DEVICE) #前面定义的DEVICE
举例如下,注意进行GPU运算的所有张量都要事先传入GPU,必须在同一设备下,一定切记!
1
2
3
4
5
model = MyConvNet().to(DEVICE)
for epoch in range(30):
for step, (D, G, L) in enumerate(train_loader):
D, G, L = D.to(device), G.to(device),L.to(device)
······
在我自己的服务上,训练的时候,直接提交到GPU的队列下,然后注意事先module load cuda/11.1(或者别的版本).
最后,祝大家调参顺利 /(ㄒoㄒ)/~~