Momonmer Types, Suprachromosomal Families (SFs) and HORs Identification
In this blog, we introduce several key concepts in centromere biology, including monomer types, suprachromosomal families (SFs), and higher-order repeats (HORs). We discuss the modern definitions of these structures and the hierarchical organization of human centromeres. We then review how biologists gradually uncovered these patterns through decades of experimental and computational studies, eventually establishing the current structural model of human centromeres.
Hierarchies in Alpha-Satellite Array
Model of Centromeric Regions
Alpha satellite DNAs are credited as the genetic substrate of endogenous centromeres in primates, starting with the new-world monkeys. No alpha satellites have been found in tarsiers and lemurs 12. In humans, arrays of alpha satellites are organized in discrete layers expanding out from a multimegabase-sized homogeneous core that is composed of chromosome-specific HORs (live or active arrays). Additional subsets of alpha satellites are often observed on one or both sides of the core in a near symmetrical formation. From center to outside, we have
-
A zone of smaller homogeneous HOR arrays (pseudocentromeres or inactive arrays)
-
An outermost layer of progressively more divergent and smaller (center-to-periphery gradient) HOR
-
Monomeric arrays (relic centromeres)
Both inactive HOR arrays and divergent arrays are often in the range of a few to hundreds of kilobases. Other distinct satellite classes, such as the classical human satellites (human satellites 1–3, or HSat1–HSat3), are of variable size (up to several megabases) and positioned in the adjacent pericentromeric regions. Segmental duplications are often observed directly flanking the satellite arrays or in centromeric transition regions extending out to the p-arm or q-arm (greater than a megabase) or between adjacent satellite arrays. The entire centromeric region can be defined by those sequences in linkage or sharing a common centromere-spanning haplotype (cenhap), which is characterized by repressed meiotic recombination3.
Centromere expansion likely goes in waves of interchromosomal transfer and amplification, where the HORs (or monomeric sequences) of the newly formed novel centromere jump from one live centromere to another and amplify in the new location to form the next generation of live centromeres (a centromeric layer) in all chromosomes or in a group of chromosomes. The remnants of the old centromere are displaced sideways, shrink, diverge, and structurally degrade.
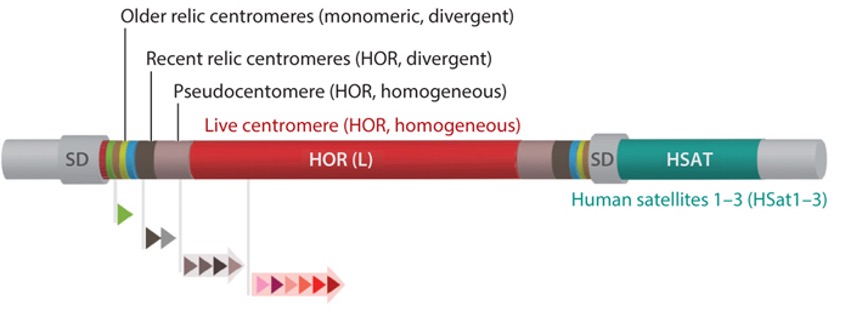
Fig 1. General genomic structure of a human centromeric region, which includes one homogeneous core made of chromosome-specific HORs (red) and the imperfect symmetrical organization of smaller arrays of various other homogeneous HORs [pseudocentromeres or inactive HOR arrays (light gray)], divergent HORs [recent relic centromeres (dark gray)], and multiple distinct divergent monomeric arrays (older relic centromeres). These regions typically include other pericentromeric satellite classes [e.g., HSat1–HSat3 (teal)] and SDs. The entire centromeric region is defined by those sequences in the cenhap, presented as gray flanking regions extending into the p-arm and q-arm. Arrayed triangles indicate alpha satellite monomers and HORs of various length and structures composed of several different monomers 1.
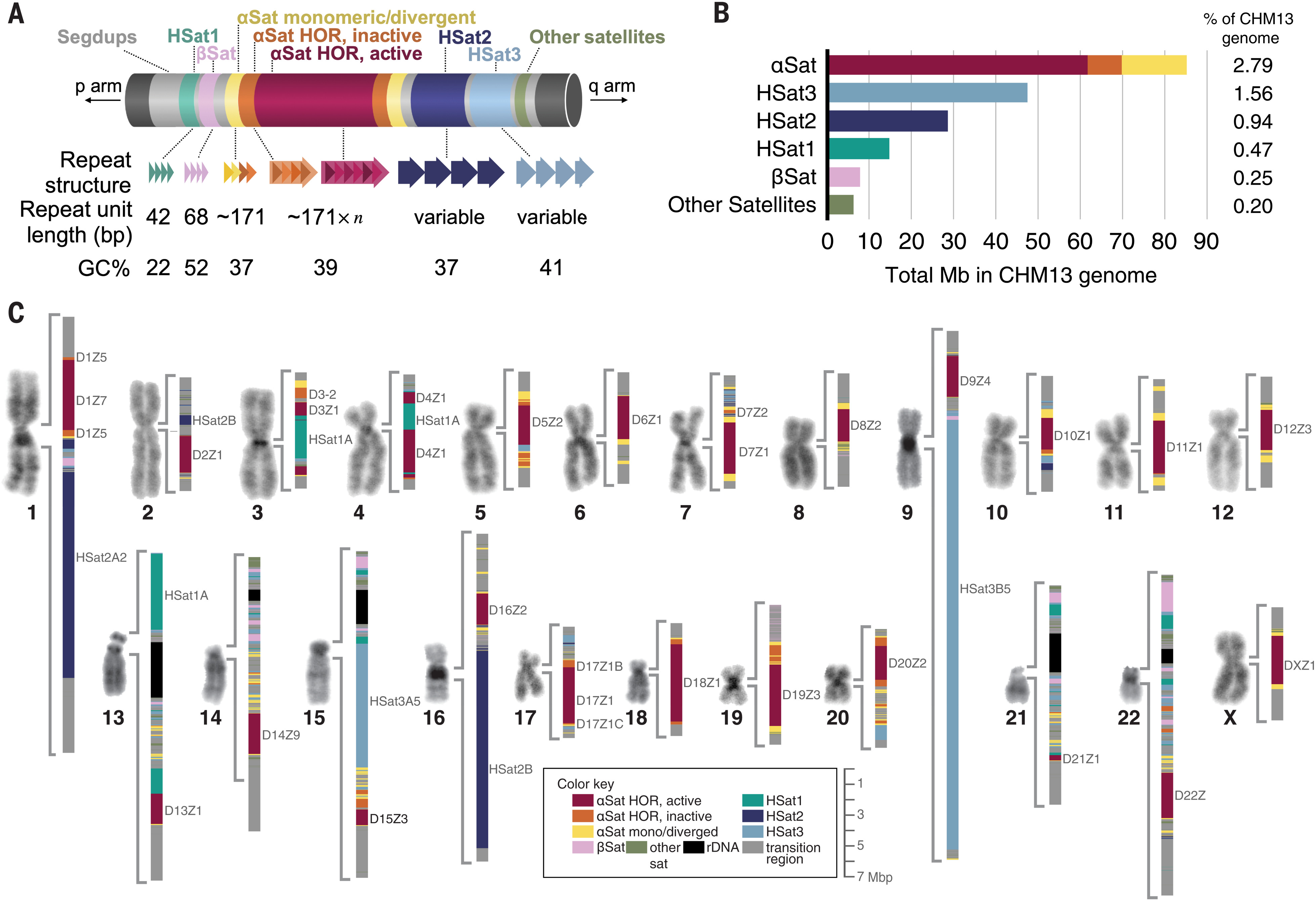
Fig 2. Overview of all peri/centromeric regions in CHM134.
Monomer Class and Monomer Type
Human centromeres contain approximately 171-bp alpha satellite repeat monomers, organized into sequences of $n$ monomers, referred to as $n$-mer HORs. The individual monomers within a HOR unit have 50–70% identity and can be distinguished such that HOR unit length is determined by where the next monomer shows nearly total sequence identity to the first monomer in the HOR. However, HOR copies appear in tandem, with the divergence between HOR copies usually being less than 5%. Monomers exhibiting less than 5% of mutual divergence belong to the same monomer type5. For cyclic shift (a monomer start site), we advocate the use of the traditional first nucleotide in the BamHI site of DXZ11.
SF and A/B type
In T2T-CHM13, we grouped αSat monomers into distinct classes belonging to 20 suprachromosomal families (SFs), identified 80 different HOR arrays and more than 1000 different monomers in HORs across the genome4. An SF is a group of HOR or monomeric arrays more closely related to each other than to the other groups. Each SF is built of its own set of monomeric classes.
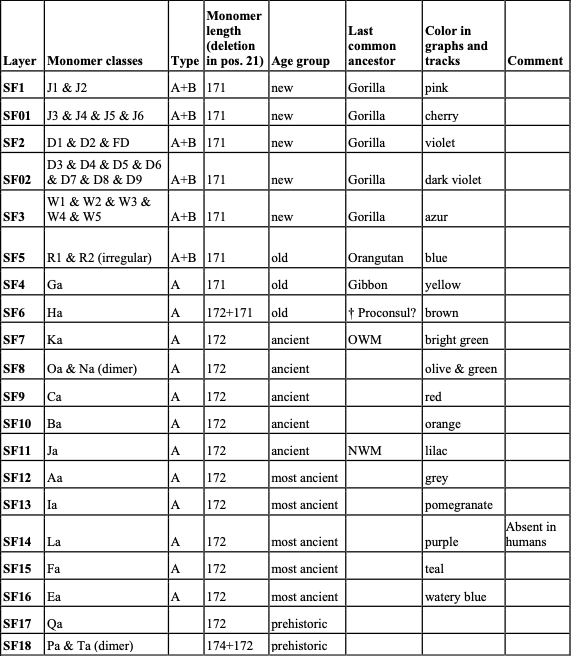
Table 1. Classification of αSat monomers into SF-specific classes. 4.
There are five major alpha satellite SFs. The new SFs (SF1–SF3) exist only in African apes, which form active (live) centromeres on all human autosomes and the X chromosome, most pseudocentromeres (or inactive arrays), and most divergent HORs. The old SF4+ and SF5 unite the dead monomeric layers as well as pseudocentromeres and divergent HOR arrays derived from them by more recent amplifications. SF5 represents centromeres that have been active at the time of the human-orangutan split. SF4+ is an umbrella group that unites a large number of old and ancient SFs, such as SF4 proper, SF6, SF7, and more, which correspond to the older primate groups1. As a notable exception, the active centromere of chromosome Y also belongs to SF46. SF5 is the immediate ancestor of the new SFs1.
You might note we have two pairs SF01 and SF1, SF02 and SF2. Shepelev et al. 7 and Uralsky et al. 8 analyzed a group of the less abundant alpha satellite sequences detected as atypical or archaic representatives of SF1 and SF2. They were shown to be the interim stages of evolution from ancestral SF5 to typical or modern SF1 and SF2 1.
The new SF1–SF3 form all of the live centromeres except for the Y and form most of the pseudocentromeric and relic inactive, or dead, HOR arrays. In SF1 and SF2 HORs, the J1 and J2 or D1 and D2 class monomers appear as internal J1J2 or D1D2 dimers, respectively, with perfect (SF1) or near-perfect (SF2) AB periodicity across arrays. In SF3 and SF5, the monomer classes (W1–W5 and R1R2, respectively) alternate in a more complex manner, and the AB pattern also does not have that simple regularity. Note that the presence of the A- or B-box in a monomer does not mean the presence of the actual pJα- or CENP-B-binding site. Boxes are just alternative configurations of the AB region that are permissive to respective sites [35–51 bp of the monomer in our cyclic shift].
HOR and naming system
SFs are groups of related HORs that share the same broad classes of monomers and reside on a number of chromosomes1.
- Homogeneous HORs usually have an overall average divergence across the whole array of about 1–2% and are chromosome-specific with a few notable exceptions among the live HOR arrays (double and triple domains).
- Sister HORs are distinct chromosome-specific sequence variants (major SqVs) within the same HOR that form smaller arrays adjacent to the live HOR [e.g., S3C17H1L (D17Z1), S3C17H1-B (D17Z1-B), and S3C17H1-C (D17Z1-C)] or pseudocentromeric subdomains in the pericentromere [e.g., S3C1H2-A, -B, -C, and -D and S2C18H2-A, -B, -D, and -E]. They are formed by monomers that differ only moderately from respective monomers of the other sister HORs (~3–7%) and may have the same or a somewhat different order of monomers.
- Haplotypes of the same HOR (slight SqVs) occupy different regions in the live HOR arrays. A haplotypic HOR region may be formed by one haplotype or by several alternating varieties. Divergence between HORs of different haplotypes may be ~1–3%, and divergence within one haplotype may be as low as 0.5%.
- Divergent HORs represent a separate entity that unites HORs that have passed completely or partially through the alleged hypermutability stage and accumulated more divergence than would be possible during their documented or estimated lifespan given the normal mutation rate. These are often partially ruined small arrays on the edges of larger homogeneous arrays, some chromosome-specific and some residing on two or several chromosomes. Intra-array divergence is typically over 10%.
SqV and StV
- Sequence Variant: The vast homogeneous core of a centromere formed by nearly identical HORs has some domains made by arrays of even more identical HORs, which share a number of characteristic mutations (a haplotype). Mutations in this case were defined as differences from the overall consensus HOR. Such haplotypes should be considered slight SqVs of a HOR (as opposed to major SqVs, which are sister HORs)1.
- Structural variants: All HORs have structural variants (StVs) that usually can be explained as in/dels of the whole monomers in the primary HOR. Also, the abundant presence of hybrid monomers where a part of one monomer of an HOR was fused to a part of the other was revealed in hg381.
The rules of the new HOR naming system
Note: the examples shown here may be fictional8.
- The name of the HOR shows SF (S), the number of a chromosome where the HOR is located (C) and the arbitrary number of the HOR in this location (H) (e.g. S1C1H1 means SF1, chromosome 1 and HOR#1 in chromosome 1). These main parts of the name may be used with optional additional indices to highlight useful information about the HOR.
- Distinct sequence variants of a HOR (as opposed to structural variants) which are segregated in separate arrays have the same name, but with a different letter index given with a hyphen (e.g. S5C1H2-A and S5C1H2-B). If there are few sequence variants of the live HOR, the L index is used instead (not together) of the -A index. Thus, in chromosome 17, there are S3C17H1L, S3C17H1-B and S3C17H1-C. Such reduction of the second letter index occurs only for the live centromere. This is done to save space and make names a bit less complicated.
- Structural variants (almost identical in sequence, but distinct in structure) of the same HOR (e.g. deleted derivatives) are not given separate names, but are treated as variants of the same HOR. These variants are given Arabic numbers (#1, #2, etc.) which are not part of the name (for example, Variant #1 of HOR S1C1/5/19H1L is 1-2-3-4-5-6 and Variant #4 of HOR S1C1/5/19H1L is 1-2-3-6/4-5-6). Note that sequence variants may also be structurally different (see below).
- SF is shown according to PERCON and the SF-track, but the SF1/5 and SF2/5 mixes, which are now known to be archaic SF1 and SF2 are shown as the respective new family SF01 and SF02.
- Chromosome location may show more than one chromosome with a slash (e.g. C13/21). That means that the same HOR is found in two different locations. If there are multiple locations one can use the CM symbol (Chromosome Multiple). If convenient, additional specification of chromosomal location is possible (e.g. C1p for the short arm and C1q for the long arm side of the centromere).
- The arbitrary number of a HOR is given irrespective of the SF. Thus, there will be S1C1H1, S3C1H2 and S5C1H3, etc. on a same chromosome.
- The number of the single live HOR in a given chromosome is always H1 and additionally marked with a letter “L” to make it easily identifiable (e.g. S1C1H1L). However, H1 does not always have to be a live centromere. Complex locations like C13/21 or CM have their separate numbering. If there are S1C1/5/19H1L and S5C5/19H1, the L index is crucial to identify a live centromere.
- An optional additional index “d” is used to show the divergent HORs, as opposed to homogeneous (e.g. S1C3H4d). Both indices L and d never occur together, as all the live centromeres are made by homogeneous HORs.
- Individual monomers of a HOR are shown as H1.1, H1.2, H1.3, etc. according to the numbering of a basic HOR as variant #1 (The basic HOR would always have the straight order). In different structural variants (#2, #3, etc.), the straight order will always be modified and will show the difference with the basic HOR. In different sequence variants (different letters of the same name), the numbering of monomers is the same as in basic HOR. If the sequence variant is structurally unchanged, the straight numbering is preserved. If in such a variant there is also a structural difference (e.g. deletion or duplication), the order may deviate from the straight (e.g. the basic HOR would have the order 1-2-3-4-5, the deleted variant would be 1-2-4-5, and duplicated variant would be 1-2-3-4-3-4-5).
- Some deletions in derived HORs may happen out of register. If one monomer is deleted which includes one half of monomer 2 and one half of monomer 3, a hybrid monomer 2/3 is formed. It has the first half of monomer 2 and the second of monomer 3. A pentamer with such a deletion will appear as a tetramer 1-2/3-4-5. Sometimes the deletion breakpoints would not be in the middle of the monomers. For instance, a hybrid monomer may have one third of monomer 2 and two thirds of monomer 3.
- If the two monomers within a HOR are highly identical and are not distinguished by HMMER they are given a combined number and appear twice in the HOR (e.g. 1-2&6-3-4-5-2&6-7-8). If an alien monomer which does not originate from the basic HOR, appears instead of a monomer in the derived HOR (or only in some of its structural variants), such monomer is denoted by a small Latin letter (e.g. 1-2-3-4-5 in the basic HOR vs. 1-2/x-x/3-4-5 in the derived variant). Such monomer may also appear as an insertion (e.g. 1-2/x-x/2-3-4-5).
- If the HOR sequence variants are structurally not simple derivatives of the basic HOR, but are related in a complex way (e.g. some monomers are the same, but some are different, or the basic HOR is divergent and the variant is a homogeneous new amplification of its segment), they were given entirely different names.
StV naming
The first part of the StV name is the HOR name (e.g. S2C8H1L). Then, after “.” follows a listing of monomer numbers included in StV separated by “_”. If monomer numbers go in a natural order (or descending natural order for the reverse strand HORs), we join the first and the last monomers in this string with “-” to indicate an interval and do not show the numbers in between (e.g. S3C11H1L.1_2_3 would appear S3C11H1L.1-3). If αSat is on the reverse strand, the monomer numbers go in reverse (e.g. S3CXH1L.1-12 would appear as S3CXH1L.12-1). Hybrids are always flanked by “_” (e.g. S2C8H1L.1-3_4/7_8-11). Rarely occurring monomers identified as monomers of another HOR or as SF class monomers (usually due to misclassification) are shown by their own name (e.g. S2C15H1L.1-4_S5C1qH6d.2_5-11 or S3C11H1L.1-2_W3_5)4.
How Centromeric Structures Were Identified
The Restriction Enzyme Horizon
The first systematic evidence for a higher-order repeat structure in human αSat did not come from sequencing but from restriction enzyme electrophoresis. When total human genomic DNA was digested with enzymes such as EcoRI and BspRI and resolved on agarose gels, characteristic “ladder” patterns were observed: a fundamental band at ~170 bp accompanied by integer multiples (340, 510, 680 bp, and so on). These ladders implied that the periodically spaced restriction sites were themselves part of a larger repeating unit. Wu and Manuelidis first described the sequence definition of one such repeat family in 1980; in situ hybridization experiments confirmed that these sequences were concentrated at the pericentromeric heterochromatin of all human chromosomes, establishing αSat as a centromeric sequence class. Critically, they established the conceptual vocabulary: the ~171 bp monomer was the “monomer,” the ladder-generating periodicity implied a “higher-order” structure, and the observation that different chromosomes showed different dominant restriction fragment lengths implied chromosome specificity. All three conclusions were later verified at single-nucleotide resolution, but their logical structure was set in place by gel electrophoresis alone.
Sanger Sequencing Reveals HOR
In 1985, Waye and Willard published the complete 2.0 kb nucleotide sequence of the X-chromosome centromeric repeat DXZ1, demonstrating that it was a 12-monomer HOR in which individual monomers showed approximately 20–40% divergence from one another yet were arranged in a fixed, tandemly repeated order.
In 1997, Willard and Waye compared the complete nucleotide sequences of 44 individual αSat monomers drawn from the HOR arrays of four chromosomes (1, 11, 17, and X). The 44 monomers exhibit an average 16% divergence from a consensus alphoid sequence, and can be assigned to five distinct homology groups based on patterns of sequence substitutions and gaps relative to the consensus. These five homology groups — designated A, B, C, D, and E — were not randomly distributed within individual HOR units; they occurred in a fixed linear order. The paper further demonstrated that this order was conserved across all four chromosomes. The five homology groups A–E of Willard & Waye 1987 map directly onto the monomer nomenclature used today: in the language of Alexandrov et al. 1988 and subsequent works, they correspond to the W1–W5 monomers that define SF3.
Cross-Hybridization Defines Three SFs
In 1988, Alexandrov, Mitkevich, and Yurov addressed this systematically by performing in situ hybridization of 18 cloned αSat fragments to human metaphase chromosomes under both stringent and non-stringent conditions. The key insight of this approach was that under stringent conditions each probe hybridized to only one or a few chromosomes (its “home” chromosome-specific family), while under relaxed conditions the hybridization spectrum revealed broader cross-reactive groupings. Comparison of the hybridization spectra obtained under non-stringent conditions and of restriction site periodicities in different chromosome-specific families allowed the identification of three “suprachromosomal” families, each located on a characteristic set of chromosomes. The three families together cover all the autosomes and the X chromosome.
The three-group chromosome assignment that paper established has remained essentially stable. Group 1 (chromosomes 1, 3, 5, 6, 7, 10, 12, 16, 19) became SF1; Group 2 (chromosomes 2, 4, 8, 9, 13, 14, 15, 18, 20, 21, 22) became SF2; Group 3 (chromosomes 11, 17, X) became SF3. The paper also deduced the ancestral periodicity underlying each family from restriction site analysis: SF1 dimeric (J1J2), SF2 dimeric (D1D2), SF3 pentameric (W1–W5).
However, a substantial fraction of αSat sequences from chromosomes 13, 14, 15, 21, 22, and Y did not hybridize strongly to any of the three groups, and their restriction patterns did not fit dimeric or pentameric ancestral periodicities. In 1993, Alexandrov et al. surveyed more than 500 αSat monomers (sequenced in their laboratory or available in the literature.) and found that most of them belonged to the well studied SF 1, 2 and 3. But 39 monomers formed a relatively homogenous family, which do not form any ancestral periodicities other than a monomeric one. Then they defined its representative consensus sequence as M1and the newly defined family was termed SF 4.
The Evolutionary Framework: SF5
The fifth SF (SF5) described in the 2001 paper consists of R1 (B-type) and R2 (A-type) monomers organized in an irregular, non-HOR arrangement. As Shepelev et al. 2009 explain, SF5 represents a transitional state: “SF5 is formed by two types of monomers, R1 and R2, alternating irregularly. R2 is similar to M1 (class A), and R1 represents the first appearance of novel class B monomers, which bind CENP-B protein and presumably have invaded the A-arrays before the great ape divergence”
SF5, in this interpretation, is the evolutionary intermediate between the purely monomeric A-type ancestral centromere and the regularly alternating AB-type HOR arrays of SFs 1–3. In the spatial architecture of living human chromosomes, SF5 arrays physically flank the active HOR arrays, reflecting their chronological position: they are the most recently “dead” centromeres, their homogenization having ceased most recently.
Decoding SF4+
SF4 was previously described as “old” αSat located peripheral to the HOR arrays, but the SF4+ designation became a catch-all for a heterogeneous mixture of sequences with very different ages and primate lineage assignments.
Using phylogenetic trees of individual αSat monomers from the largely sequenced pericentromeric regions of chromosomes 8, 17, and X, the paper identified distinct monomer clades that each formed compact, contiguous chromosomal domains. Crucially, the study demonstrated that these domains were partially symmetrically arranged around the active HOR array on each chromosome and were shared between non-homologous chromosomes — evidence that each layer represents the remnant of a genome-wide centromere replacement event, rather than chromosome-specific divergence.
The layer structure was assigned to specific primate lineages using two independent dating methods: L1 retrotransposon content (measuring when homogenization ceased and the sequence became accessible to insertions) and comparative genomics in extant primates. This yielded an age chronology for each layer ranging from approximately 16 Myr (SF5) to over 40 Myr (H4 class), corresponding to centromere generations from before the great ape–gibbon split to before the New World / Old World monkey separation.
Computational Annotation in the Reference Genome: PERCON, HumAS-HMMER
The release of hg38 in 2014 offered a partial opportunity: for the first time, centromeric gaps in the reference assembly were filled with “reference models” (RMs), described by Miga et al. 2014 (collections of all WGS reads, that match a certain HOR, put into a contig by the stochastic approach of using a generative Markov process). These models were not true linear sequences, but they enabled the first comprehensive genome-wide αSat annotation using the PERCON program, which Shepelev et al. 2015 describe and deploy.
PERCON operated by a Bayesian classifier that assigned each identified ~171 bp monomer to one of 12 known monomer classes (J1, J2, D1, D2, W1–W5, R1, R2, M1) or designated it unclassified. As Shepelev et al. 2015 describe: “Every monomer was classed into one of the 12 known standard monomer classes or defined as unclassed (Um) or random (Xm) by a simple Bayesian classification procedure that utilized consensus matrices of the 12 classes of monomers together with the random matrix”. This approach — classifying each monomer individually against a fixed set of reference consensus sequences — is the methodological core that was subsequently inherited by HumAS-HMMER and ultimately by AS-HMMER-SF in the T2T paper. The PERCON SF-track from hg38 served as the ground-truth reference against which all subsequent computational methods were validated.
In 2019, Uralsky et al. advanced the annotation from the SF-monomer level to individual HOR monomers, developing the HumAS-HMMER tool and simultaneously proposing a systematic HOR naming convention as we mentioned above. The HumAS-HMMER tool itself introduced another methodological innovation: instead of using single Bayesian consensus matrices as PERCON did, it employed profile hidden Markov models (HMMs), allowing each monomer position in a HOR to be represented by a statistical model of the variation observed across multiple sequenced copies. For “divergent” relic HOR arrays — HOR-like structures with 9–15% intra-monomer divergence, representing ancient centromeres never homogenized to modern levels — the tool used multiple sequence alignment (MSA) profiles rather than single-monomer profiles. This allowed the first annotation of what Uralsky et al. termed “dead relic HORs”: divergent, degraded remains of actual centromeres of our ancestors.
The T2T Resolution
The Altemose et al. 2022 paper is the first to apply the αSat classification framework to an assembly in which the centromeric sequences are complete: not probabilistic reference models but actual linear sequence contigs spanning from one chromosome arm to the other. The expansion of the annotation system relative to all prior work is quantitatively substantial. From the five SFs recognized in the early 2000s, the T2T annotation recognizes 20. From the 12 monomer classes of PERCON, the AS-HMMER-SF tool used in the T2T paper recognizes 39.
The validation criterion for each new SF was stringent: “Annotation success in both hg38 and CHM13 was confirmed by the fact that, without exception, all SF assignments matched those provided by the Shepelev et al., 2015 PERCON annotation and the assignments made by phylogenetic analysis and manual mapping in Shepelev et al., 2009 and Uralsky et al., 2019”.
The 2022 paper introduced a fully automated pathway for monomer and HOR inference using the StringDecomposer algorithm and the HORmon pipeline. It outputs same canonical HORs for active arrays.
Reference
-
Miga, Karen H., and Ivan A. Alexandrov. “Variation and evolution of human centromeres: a field guide and perspective.” Annual review of genetics 55.1 (2021): 583-602. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9
-
The Evolutionary Origin of Man Can Be Traced in the Layers of Defunct Ancestral Alpha Satellites Flanking the Active Centromeres of Human Chromosomes. ↩
-
Langley, Sasha A., et al. “Haplotypes spanning centromeric regions reveal persistence of large blocks of archaic DNA.” elife 8 (2019): e42989. ↩
-
Altemose, Nicolas, et al. “Complete genomic and epigenetic maps of human centromeres.” Science 376.6588 (2022): eabl4178. ↩ ↩2 ↩3 ↩4
-
Glunčić, Matko, et al. “Precise identification of cascading alpha satellite higher order repeats in T2T CHM13 assembly of human chromosome 3.” Croatian medical journal 65.3 (2024): 209-219. ↩
-
Makova, Kateryna D., et al. “The complete sequence and comparative analysis of ape sex chromosomes.” Nature 630.8016 (2024): 401-411. ↩
-
Shepelev, V. A., et al. “Annotation of suprachromosomal families reveals uncommon types of alpha satellite organization in pericentromeric regions of hg38 human genome assembly.” Genomics data 5 (2015): 139-146. ↩
-
Uralsky, L. I., et al. “Classification and monomer-by-monomer annotation dataset of suprachromosomal family 1 alpha satellite higher-order repeats in hg38 human genome assembly.” Data in brief 24 (2019): 103708. ↩ ↩2
Enjoy Reading This Article?
Here are some more articles you might like to read next: